(著)山拓
(注)脳科学における新皮質の理論仮説の予測符号化(predictive coding)です。画像符号化にもちいられる手法ではありません。
日本語で詳しく書かれた記事が無かったので、predictive codingについて自分でまとめてみました。
※Karl Fristonの自由エネルギー原理(Free energy principle, FEP)については触れません…。
脳は外部環境を予測する
脳は不良設定問題 (ill-posed problem)を解けると言われます。不良設定問題というのは、問題を解くための条件が不足している問題のことです。例えば、網膜に投影された2D画像から3D構造の認知という逆問題などがあてはまります。では脳はどうやって不良設定問題を解いているかというと、解けるように条件を勝手においているためです。この条件とは、例えば「光は上から照らされている」、「テクスチャが密なほど遠くにある」などです。これは経験によって得た確率分布であるとも言い換えられます。
それでは、どのような学習によりこれらの条件を脳は獲得しているのでしょうか。今現在(2018年)のところは「外部環境を予測する教師なし学習」であると言われています。
視覚について考えてみましょう。まず、網膜の視細胞が光刺激を受け取り、LGN(外側膝状体)→V1(一次視覚野)→V2→… と低次から高次へ情報を伝達します。これは順行性結合(feed-forward connection)です。この過程で外界における隠れ変数の推定が行われます。隠れ変数には物体の大きさ、物体間での前後関係、奥行き、運動、光の当たり方、色など物体に関する多種多様な構成要素が含まれます。
こうして生まれた外界の仮説を用いて、今度は外界に対する予測を脳は生み出します。シミュレーションする、と言ってもいいかもしれません。予測は高次から低次に送られますが、これは逆行性結合(feed-back connection)です。こうして脳は、過去に得られた情報から未来の網膜像を予測し、実際に得られた網膜像と比較します。それらが一致していれば、つまり正しく予測できていれば問題はないのですが、予測できていなければ予測を生み出した仮説が間違っていた、つまり正しくエンコードできていなかったということになります。よって、変数の推定および予測を生み出したネットワークを最適化するため、予測と実際の入力との誤差信号が再度、順行性で送られます。少し曖昧な言葉が多くなりましたが、詳しいことは後で説明します。
何が素晴らしいかというと、教師なし学習ができるという点です。幼少期に大きさ当てゲームや奥行き当てゲームをしなくとも、網膜像の予測により物体の大きさや奥行きなどが学習できるのです。直近で読んだディープラーニングの論文だと"Unsupervised Learning of Depth and Ego-Motion from Video"[2]がよい例です。これは動画から奥行き(depth)と自己運動(ego-motion)を教師なし学習で学習するという論文です。概略図は次の通り。
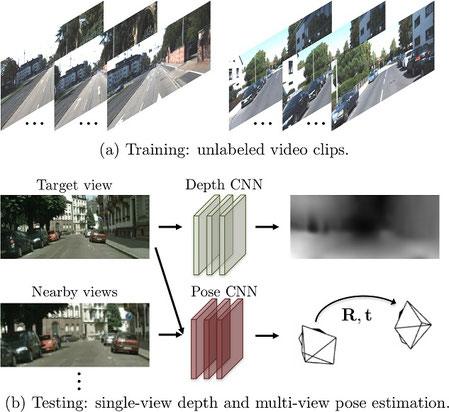
画像から奥行きを推定するDepth CNNとt, t+1における入力画像の差異から自分がどのように動いたか(自己運動, ego-motion, ここでは車載カメラなので車がどう動いたか)を推定するPose CNNがあります。このDepth CNNとPose CNNを、それぞれが推定した奥行き、回転、並進から再構成した画像と実際の画像との誤差により教師なし学習を進めます。
predictive codingについて論文内で言及はなかったですが、将来の網膜像を予測することによる学習ということができます。この研究を改良したvid2depthも素晴らしいです。
ここまで脳(の新皮質)全体としての予測を用いた学習について考えましたが、predictive codingはもう少し小さいネットワーク領域における仮説です。もちろん、小さいネットワークが積み重なって、ここまでの内容のように全体として予測を行っているということではありますが。
それではpredictive codingは何か、の前に何故predictive codingという仮説が必要となったかについて説明します。
視覚経路の双方向結合
先に述べたように、視覚経路には順行性のみならず逆行性の結合も存在します。一部の領域(V1など)では順行性よりも逆行性の結合の方が多いほどです。単に情報をエンコードするだけなら順行性の結合だけで良いわけです。
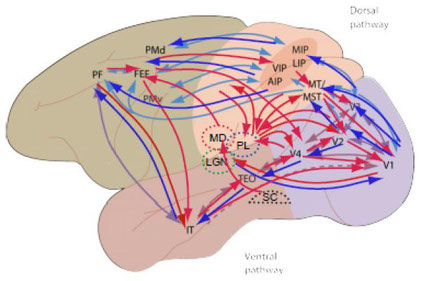
Gilbert, C. D., et al. [3]より。元の図はカンデル神経科学(図25-7B)
この問題に対して、日本の川人先生らは「高次から低次への投射は、低次から高次への逆変換となっている」という仮説を1993年に提唱しました[4]。
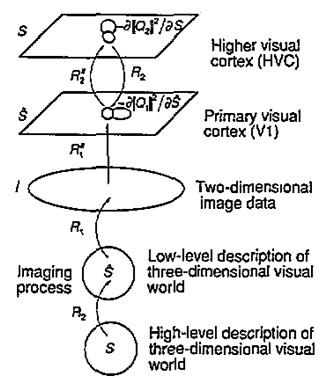
この仮説はpredictive codingのものと同じです。ただし、洗練された計算論的モデルに落とし込んだのは、1999年のRao, Ballardによる研究[5]です。
predictive codingのモデル
それでは、predictive codingのモデルを見ていきましょう。Raoらによるオリジナルのモデルより先に簡単なモデルから説明します。それぞれのモデルは完全に同一ではないので注意してください。
簡単なモデル

※このモデルは以下の動画を参考にしました。
Rao&Ballardによるモデル
本題のRao先生によるモデルです。内容自体は今まで言ってきたことと変わりません。下層のニューロンは入力と上層からの予測の誤差を上層に伝える、というものです。図の下側は上側のPredictive Estimatorの中身を詳しく書いたものです。
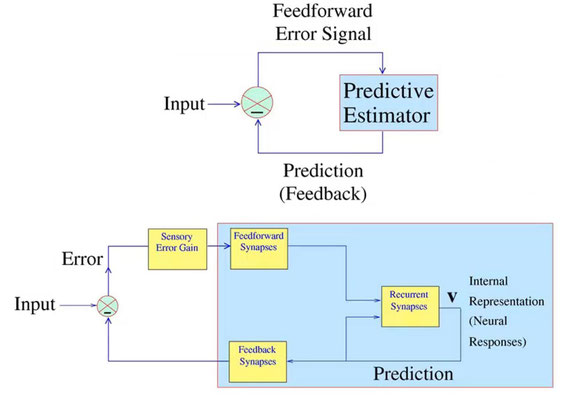
CourseraのComputational Neuroscience, Week7より。講義の詳細はComputational-NeuroScience : Week0を参照してください。
なお、Rao先生は『脳の計算機構―ボトムアップ・トップダウンのダイナミクス』という本に著者として参加しており、predictive codingの解説を執筆しています。たぶんレビュー論文を翻訳したのでしょうが。2005年の本で内容が古いので、読む際は注意が必要です。
詳細なモデル
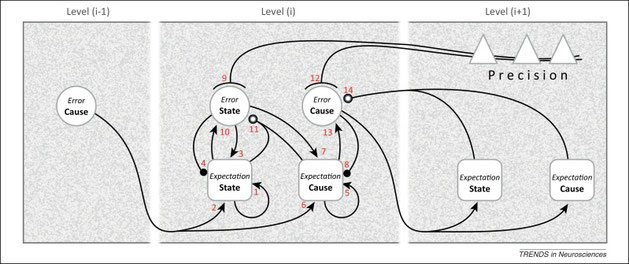
Shipp S, et al., [1] より
もうちょっと詳しくモデル化したのが上図です。
PredNetについて
predictive codingのモデルをDeep Neural Networkのモデルに組み込んだのが2016年に発表されたPredNetです[6]。
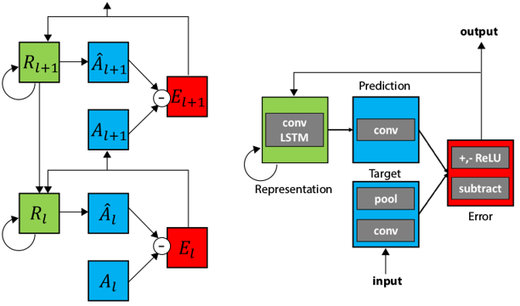
各層には4つの素子があり、Target, Representation, Prediction, Errorという構成です。Targetは下層からの出力(誤差信号)をエンコードします。RepresentationはRecurrent unitで、上層からの出力、側方からの誤差信号、1ステップ前の自分の出力、を受け取ります。Representation unitはTargetの予測をするPrediction unitに投射し、入力の予測が出力されます。ErrorはPredictionとTargetの誤差です。Errorは上層に送られます。このErrorが小さくなるように学習を進めます。
PredNetに関しては実装をしてみましたので、次の記事を参考にしてください。
以下の動画はDavid Cox先生による解説です。2018年4月ぐらいの動画で、ヘビの回転錯視に関する論文[8]の説明もあります。

関連する人工神経回路のモデル
ちょっと違うかもしれませんがDavid HaによるWorld Models [arxiv]は外界の予測をするということで、predictive codingっぽい要素を含みます。
参考文献
[1] Shipp S, Adams RA, Friston KJ. Reflections on agranular architecture: predictive coding in the motor cortex. Trends in Neurosciences. 2013;36(12):706-716. doi:10.1016/j.tins.2013.09.004. [NCBI]
[2] T. Zhou, M. Brown, N. Snavely and D. G. Lowe, Unsupervised Learning of Depth and Ego-Motion from Video, 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017, pp. 6612-6619.
[3] Gilbert, C. D., Li W. Top-down influences on visual processing. Nature reviews Neuroscience. 2013;14(5):10.1038/nrn3476. doi:10.1038/nrn3476. [NCBI]
[4] Kawato M, et al. A forward-inverse optics model of reciprocal connections between visual cortical areas. Network. 1993;4:415-22. [pdf]
[5] Rao R.P., Ballard D.H. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 1999;2:79–87. [PubMed] [Researchgate]
[6] W. Lotter, G. Kreiman, and D. D. Cox. Deep predictive coding networks for video prediction and unsupervised learning. ICLR, 2017. [hp][arxiv]
[7] William Lotter, Gabriel Kreiman, David Cox, A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception. 2018. CoRR abs/1805.10734 [arxiv]
[8] Watanabe E, Kitaoka A, Sakamoto K, Yasugi M, Tanaka K. Illusory Motion Reproduced by Deep Neural Networks Trained for Prediction. Frontiers in Psychology. 2018;9:345. doi:10.3389/fpsyg.2018.00345. [PubMed]
[9] Shipp S. Neural Elements for Predictive Coding. Frontiers in Psychology. 2016;7:1792. doi:10.3389/fpsyg.2016.01792. [NCBI]
コメントをお書きください
Safety Driving (Monday, 12 October 2020 12:28)
brain-ai 2020で長井教授の講演を拝聴し、いろいろと調べている途中でここに来てみました。興味深い解説です。4年生ですか?
経路に制約のない自動運転:Lv5が大衆車に搭載されるのは数十年先なので、人の運転が安全に変容する車の研究開発をしています。
運転中の予測符号化には個人差があり、外界リスクとの因果性を説明可能ではないと考えています。数年来、貴学とは縁があります。