(著)山たー
最近はDNN(RNNやLSTMなど)を用いた文章生成が盛んですが、時代を逆行して、マルコフ連鎖による文章生成(botなどのいわゆる『人工無能』)をPythonで行ってみました。マルコフ連鎖については以前書いた記事のマルコフ連鎖 (Markov chain)を参照してください。
マルコフ連鎖でどうやって文章を生成するか
まず、文を読み込んで形態素に分割し、形態素をノードとするマルコフモデルを作成します。例えば、「私はトマトが好きです。」と「私は休みが欲しい。」という2つの文を読み込むと、次のようなモデルを作ることができます。
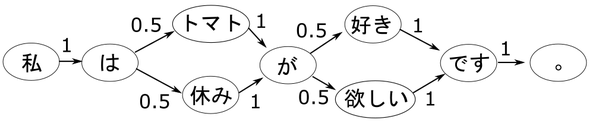
矢印のそばにある数字は遷移確率です。
ここで、ランダムにノードを選択すると
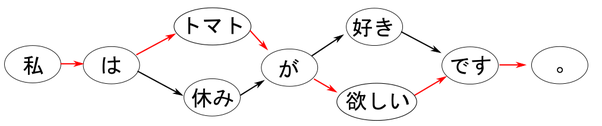
「私はトマトが欲しいです。」という新しい文ができます。他に「私は休みが好きです。」という文も生成できます。
よって、マルコフモデルを用いて文を生成するには
- 文を形態素に分割
- 形態素をノードとしたマルコフモデルを作成
- 文頭のノードをランダムに選び、ランダムにノード間を遷移
- 遷移した過程に存在したノードの形態素を繋げる
というステップを踏めばよいことが分かります。ただし、より「ちゃんとした」文章にするため、1つのノードに複数の形態素のまとまりを対応させることが多いです(例えば、「私」と「は」ではなく、「私は」というように2つの形態素を1つのかたまりと見る、など)。
形態素解析エンジン(Janome)のインストール
形態素解析エンジンと言えば、MeCabが使われるのですが、環境がWindowsなので、インストールしやすいJanomeを使うことにしました。Janomeのインストールは
pip install janome
で一発です。これがMeCabだと苦しむことになります。MacやLinuxだとMeCabの方が良いと思います。
Pythonによる実装
MeCabとPythonでマルコフ連鎖を書いてみる(改)の大部分を参考にしました。
# -*- coding: utf-8 -*-
import random
from janome.tokenizer import Tokenizer
# Janomeを使用してテキストデータを単語に分割する
def wakati(text):
text = text.replace('\n','') #改行を削除
text = text.replace('\r','') #スペースを削除
t = Tokenizer()
result =t.tokenize(text, wakati=True)
return result
#デフォルトの文の数は5
def generate_text(num_sentence=5):
filename = "test.txt"
src = open(filename, "r").read()
wordlist = wakati(src)
#マルコフ連鎖用のテーブルを作成
markov = {}
w1 = ""
w2 = ""
for word in wordlist:
if w1 and w2:
if (w1, w2) not in markov:
markov[(w1, w2)] = []
markov[(w1, w2)].append(word)
w1, w2 = w2, word
#文章の自動生成
count_kuten = 0 #句点「。」の数
num_sentence= num_sentence
sentence = ""
w1, w2 = random.choice(list(markov.keys()))
while count_kuten < num_sentence:
tmp = random.choice(markov[(w1, w2)])
sentence += tmp
if(tmp=='。'):
count_kuten += 1
sentence += '\n' #1文ごとに改行
w1, w2 = w2, tmp
print(sentence)
if __name__ == "__main__":
generate_text()
今回はけものフレンズのWikipediaのあらすじをtest.txtに保存し、同じディレクトリにおいて実行してみました。
結果
電池が完全に充電され、自らを「危機」からヒトと断定されていたカピバラ(声 - 尾崎由香)の悲鳴を聞く。
ゲートの前にいた木材にぶつけ倒してしまったことで溶岩になって遊ぶ。
山の噴火が活発化すると、サーバルを救出するが、海へと足をすすめるのち、二人は道中、サーバルが運転するジャパリバスをかばんに贈る。
ゲートの前にいたハシビロコウは、巨大なセルリアンであった。
やべえよやべえよ…。
コメントをお書きください